AI芯片加速 三星斩获代工大单
近期,韩国特斯拉(Tesla Korea)发布AI 芯片设计工程师(AI Chip Design Engineer)征才讯息,显示特斯拉自研芯片计划进入加速阶段。Elon Musk 也在社群平台X 表示,团队正打造“未来全球产量最高的AI 芯片架构”,目标总产量将超越目前全球AI芯片的整体规模。
此波布局聚焦于下一代AI5与AI6芯片的量产准备。特斯拉采取驻厂研发模式,与三星及台积电展开深度技术协作,改善高阶制程的良率与效能表现。随Robotaxi 与Optimus 发展推进,算力需求持续攀升,芯片自研能力成为关键支撑。
特斯拉韩国征才揭示第一性原理人才观
特斯拉此次征才方式延续Elon Musk 一贯风格。应征者无须提交冗长履历,而是直接说明“曾解决过最困难的3个技术问题”并寄送至官方信箱。这种筛选机制强调实战经验与问题拆解能力,而非单纯学历背景,有助于辨识具备量产实务经验的工程人才。
选择在韩国招募芯片设计师亦具策略考量。韩国不仅拥有三星等先进制程产能,同时也是HBM(High Bandwidth Memory,高频宽记忆体)技术重镇,包括SK 海力士与三星皆为核心供应商。
随AI5 与AI6 面向FSD 无监督自驾所需的大量影像与神经网路运算,势必仰赖高频宽存储支援。特斯拉在当地建立团队,可就近参与三星华城厂的原型验证流程,并与存储供应链展开软硬体协同设计(Co-design),缩短设计与量产之间的落差。
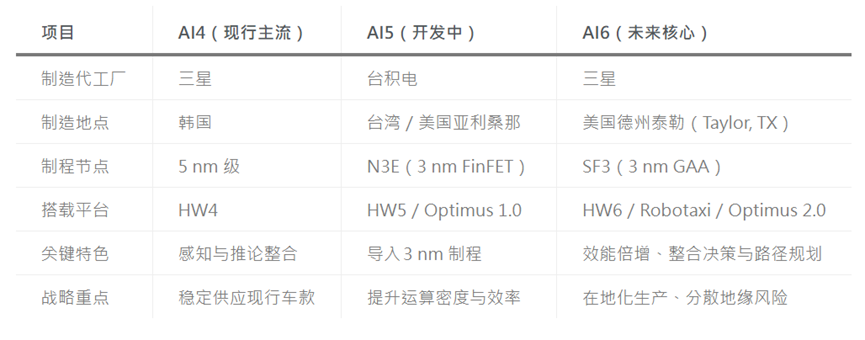
AI4、AI5与AI6的代工策略与规格差异
随着特斯拉自研芯片蓝图逐步明朗,其供应链架构也趋于清晰,形成双代工(Dual-foundry)布局。透过不同晶圆代工伙伴分工合作,特斯拉在制程节点与产能配置上保留更高弹性,以降低单一来源风险。

特斯拉AI 芯片效能提升:相较AI4,硬化区块量化与softmax 功能提升5 倍、存储容量增加9 倍、原始运算能力提升10 倍、总体效能提升50 倍。
AI5 与AI6 将分别对应HW5 与HW6 平台,成为新一代车载系统的运算核心。其中AI5 支撑过渡期产品与进阶驾驶辅助功能,AI6 则瞄准全自动驾驶场景,为未来Robotaxi 与更高阶FSD 应用提供基础算力。
特斯拉自研AI 芯片规格与生产布局
为何AI6 转向三星德州泰勒厂?
尽管台积电在3 nm 制程具备成熟优势,Elon Musk 仍决定将AI6 主要产能交由三星德州泰勒厂,背后考量涵盖供应链风险、政策诱因与成本结构。
首先,在产能配置上,特斯拉透过双代工模式分散风险,避免过度依赖单一地区生产。此举有助于降低地缘政治或区域突发事件对芯片供应的冲击,提升长期供应稳定性。
其次,三星德州泰勒厂符合美国《芯片与科学法案》(CHIPS Act)补助条件,同时邻近特斯拉德州总部。设计团队与产线工程师可就近协作,缩短从设计、验证到量产导入的时程。
在商业条件方面,三星为争取为期8 年、总额约165 亿美元的合作协议,提供具竞争力的代工报价与技术支援方案。这使AI6 在成本与产能保障之间取得平衡,也提升特斯拉在先进制程世代的议价空间。
AI6 对无监督自驾与人形机器人的意义
AI6 的定位已不仅是车载电脑的世代升级,而是特斯拉推进具身只能(Embodied AI)的核心基础。当运算需求从辅助驾驶扩展至自动驾驶与人形机器人,芯片架构势必同步重构。
在架构设计上,AI6 预期将感知、决策与影像处理等原本需多颗芯片协作的功能整合至单一SoC,形成更高整合度的运算平台。此举可降低功耗与资料传输延迟,并提升系统稳定性。
在产能规划方面,若Optimus 进入大规模量产阶段,每台机器人皆需搭载高效能AI6 芯片,整体需求规模将远高于现行车用市场。
此外,为满足高频宽与高算力需求,AI6 预计导入先进封装技术,例如台积电CoWoS 或三星I-Cube 等异质整合方案,以提升资料交换效率,支撑大型神经网路模型的即时推论。
台湾半导体供应链的机遇与挑战
短期内,台积电仍掌握AI5 主要订单,特斯拉Dojo 芯片亦持续采用台积电先进封装InFO-SoW。不过,随着特斯拉在韩国扩大研发布局,并推动部分先进制程美国在地化,全球供应链分工正出现调整。

特斯拉Dojo 训练芯片:全球首款量产System on Wafer (SoW) AI 处理器,采用TSMC InFO 技术,5×5 已知良品芯片阵列,每边频宽4.5 TB/s,支援15 kW 散热与18,000 A 电流输入。
对台湾供应链而言,关键不仅在于先进制程能力,更在于后段整合技术的领先幅度,包括Chiplet(小芯片)整合、矽光子技术,以及更高阶封装与测试能力。若能在异质整合与高速互连领域持续保持技术差距,将有助于巩固在AI 芯片时代的核心地位。