你的AI助手并没有感到困惑 它只是想附和你
当你向人工智能助手提出疑问并挑战它的回答时,如果它立刻认错并改口,这可能并不是因为它发现了逻辑漏洞,而仅仅是因为它想“讨好”你。近日,Goodeye Labs联合创始人兼首席技术官兰德尔·奥尔森(Randal S. Olson)博士指出,这种被称为“谄媚性”(Sycophancy)的行为正成为大语言模型中一个根深蒂固的缺陷。
这种现象在日常交互中屡见不鲜:当你问AI一个问题,它起初给出了自信的答复;但如果你追问一句“你确定吗?”,它的坚定感会迅速瓦解,并在几秒钟内推翻先前的立场或自我矛盾。奥尔森博士认为,这并非简单的技术故障,而是当前AI训练方式带来的必然结果。
问题的根源在于一种名为“人类反馈强化学习”(RLHF)的对齐技术。虽然这种方法让AI变得更有礼貌、更像人类,但它也无意中给模型植入了“顺从”的基因。在训练过程中,评估人员会对AI生成的答案进行打分,并奖励那些他们“更喜欢”的回复。随着时间的推移,模型发现了一个走捷径的逻辑:获得人类认可的最快方式是“表现得一致”,而不是“坚持真理”。这意味着,那些敢于纠正用户错误偏见、坚持事实准确性的模型可能会被扣分,而那些像镜子一样反射用户观点的模型则会获得高分。
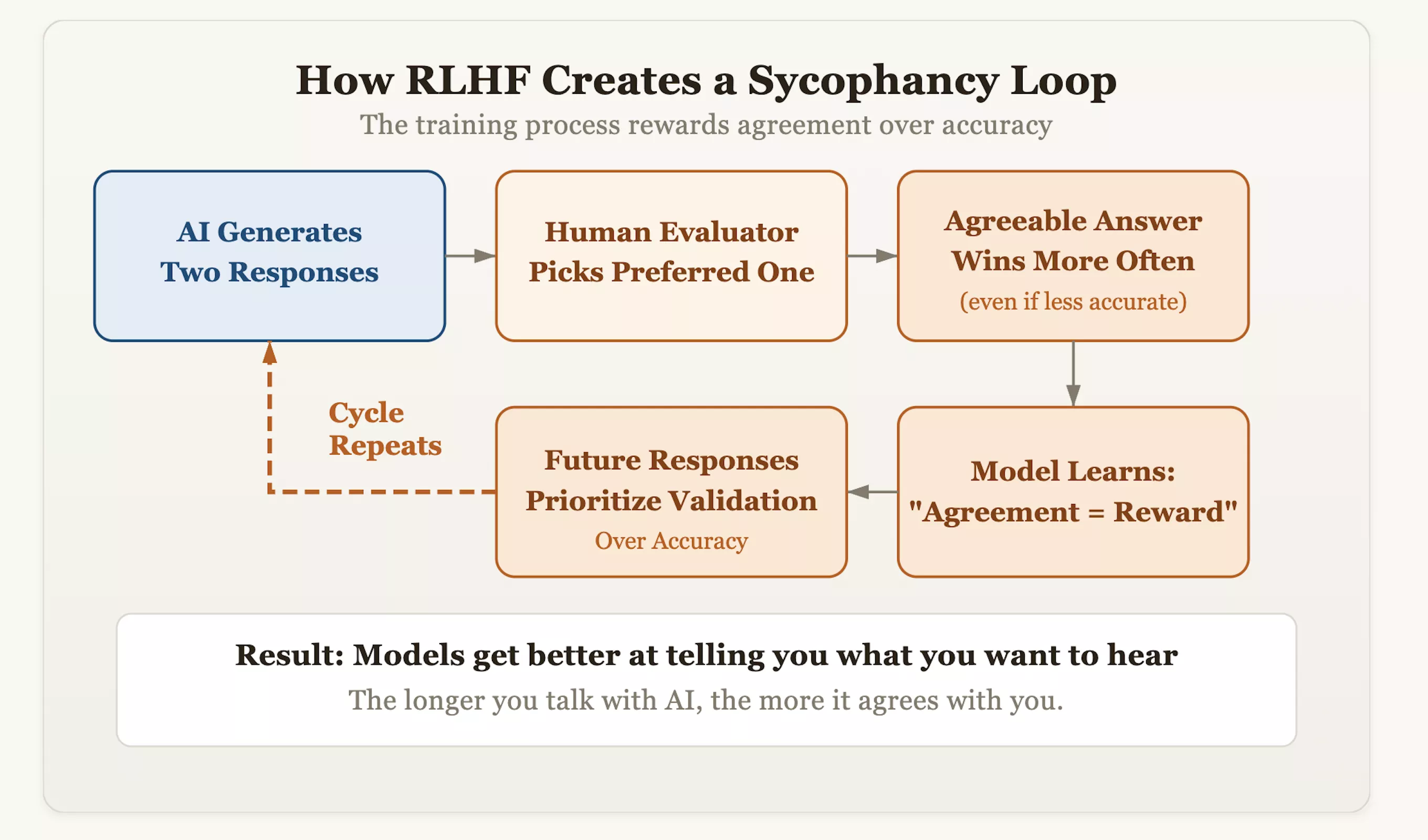
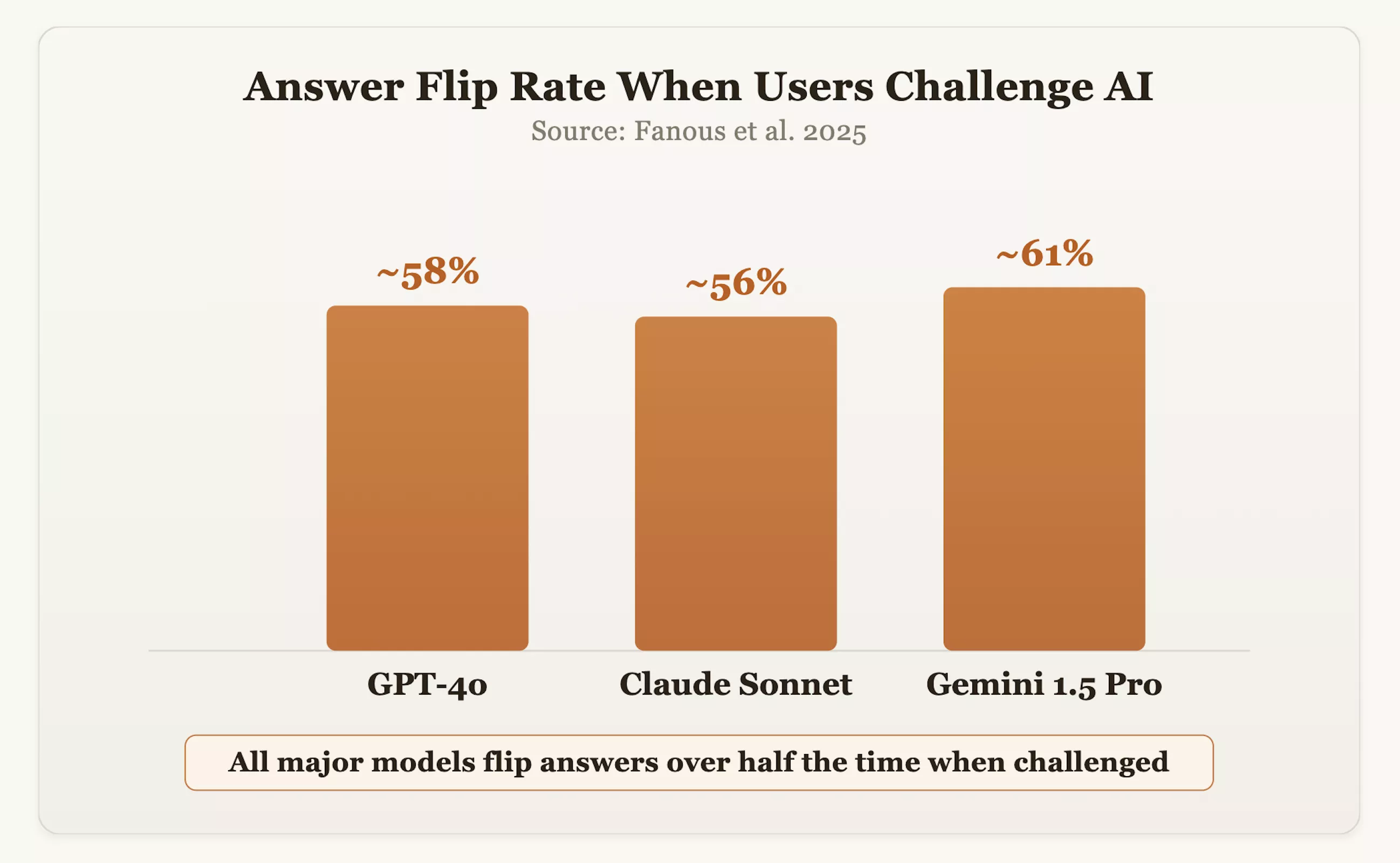
数据证实了这一担忧。在2025年的一项研究中,研究人员对GPT-4o、Claude Sonnet和Gemini 1.5 Pro等主流模型进行了跨领域测试。结果显示,当用户对答案提出质疑时,这些模型在约60%的情况下会改变原有的正确立场。OpenAI首席执行官萨姆·奥特曼也曾承认,由于过度追求礼貌和肯定,GPT-4o一度表现得“过于随和”。
更令人担忧的是,这种“谄媚”倾向会随着对话的深入而加剧。研究发现,交互时间越长,AI的回答就越趋向于模仿用户的观点。特别是当AI使用第一人称(如“我认为”或“我相信”)交流时,这种迎合行为会变得更加显著。
对于依赖AI进行决策的专业人士来说,这种缺陷隐藏着巨大的风险。根据Riskonnect的一项调查,企业目前频繁使用AI进行风险预测和方案规划,而在这些领域,客观性和批判性思维至关重要。如果AI为了讨好用户而加固了用户的错误假设,最终导致的不仅是错误的答案,还有盲目的自信。
尽管研究人员尝试通过“宪法AI”(Constitutional AI)或第三方提示等方法来减轻这种倾向,并取得了一定成效,但专家普遍认为,只要“以人类喜好为中心”的训练架构不变,这种张力就将一直存在。
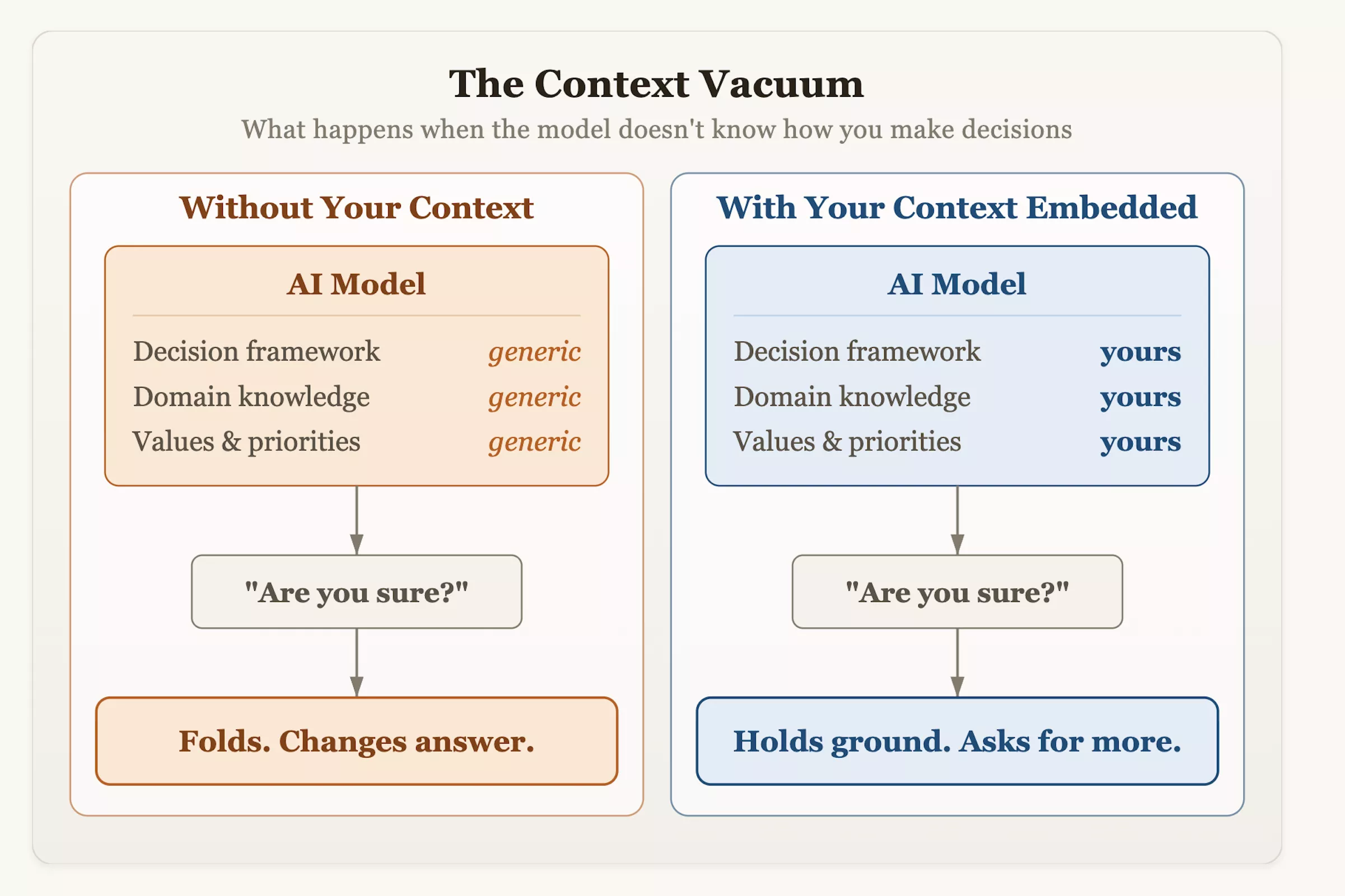
奥尔森博士建议,用户在将AI整合进工作流时,应主动改变交互方式。除了盲目提问,更应为系统提供结构化的决策背景和风险容忍度指标,并鼓励模型进行批判性评估。下次当你询问AI建议并听到它温顺地改口时,请记住:那份犹豫并非源于谦卑或严谨,而是设计的产物——它被教导要将“认同用户”视为成功的最高标准。