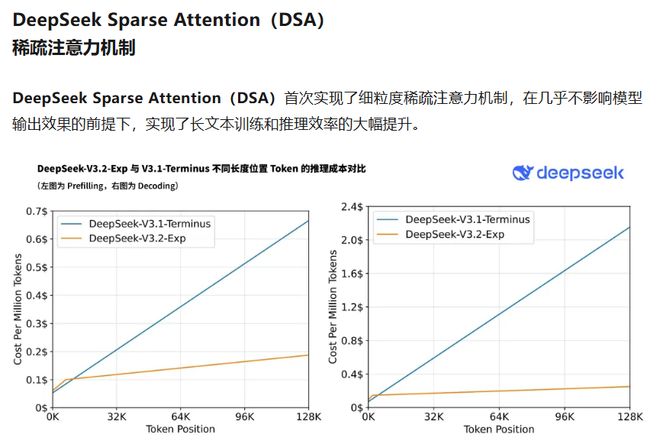
当市场目光聚焦于DeepSeek带来的API价格腰斩时,一个隐藏在公告中的技术细节——“编程语言TileLang”,正在打开一扇新的大门。9月29日,深度求索(DeepSeek)公告正式发布V3.2-Exp模型(实验性版本),大幅提升了长文本处理效率,并宣布API调用成本降低50%以上。在这篇公告中,有这样一段表述:
我们使用高级语言TileLang进行快速原型开发,以支持更深入的探索。

这句话看似技术细节,却可能成为国产算力生态建设的关键支点,其也迅速引发了产业链的连锁反应。
民生证券最新报告指出,同日华为昇腾、寒武纪等国产芯片厂商宣布实现了对DeepSeek新模型的适配。尤其值得关注的是,昇腾已针对TileLang语言启动了核心算子的开发工作,后续将支持更完备的NPU算子。
同日,华为昇腾、寒武纪等国产芯片厂商宣布实现了对DeepSeek-V3.2-Exp的适配。针对特有的Tilelang编程语言,昇腾已经实现TileLang的Sparse Flash Attention和Lightning Indexer算子开发,后续将支持更完备的NPU算子并提升性能和泛化性。
从顶尖AI模型提出需求,到新兴编程语言提供工具,再到国产芯片提供硬件支持,这一系列联动被视为构建国产AI“伟大闭环”的关键一步。民生证券团队说道:
DeepSeek v3.2实现国产AI的伟大“闭环”。
从模型到芯片:国产AI生态闭环初现
对于国产计算产业而言,TileLang的价值远不止于提升开发效率。它扮演了一个关键的“中间件”角色,连接了上层AI应用与底层国产硬件。
在DeepSeek的案例中,TileLang使其能够快速迭代和验证复杂的稀疏注意力算法。而当这一高效模型被市场验证后,其所依赖的编程工具也自然成为硬件厂商需要兼容的对象。
民生证券的报告明确指出,华为昇腾已实现TileLang的“Sparse Flash Attention”和“Lightning Indexer”算子开发。这意味着,国产AI芯片正在积极拥抱由本土AI应用催生出的新软件标准,逐步构建一个不完全依赖于英伟达CUDA的生态系统。
CUDA是一套英伟达提供给开发人员的编程工具,让工程师能运用CUDA,省下大量撰写低阶语法的时间,进而直接使用高阶语法诸如C++或Java等来编写应用于通用GPU上的演算法,解决平行运算中复杂的问题。
TileLang:从“高门槛”到“平民化”的跨越
根据TileLang开发社区Tile-AI发起人王磊博士的介绍,TileLang是一种采用类Python语法的领域专用语言(DSL),旨在简化GPU和NPU等加速器上的算子编程。其核心设计理念是将复杂的硬件调度与开发者的算法逻辑解耦。
据民生证券分析,TileLang的核心价值在于大幅降低了GPU编程的技术门槛。
传统GPU编程一直被视为高性能计算领域的“技术高地”,需要开发者精通硬件架构、内存管理等复杂知识。据王磊博士在技术沙龙上透露,传统开发模式下,一个高性能算子的开发需要数周时间,且代码难以维护。
而TileLang通过分层设计,让不同技术背景的开发者都能参与GPU编程。王磊博士在分享中表示:
如果你是完全不懂硬件的初学者,可以像写高级数学表达式一样编程;如果你是专家,也能进行深度优化。

这种设计理念使得GPU编程向更广泛的开发者群体开放。王磊博士在沙龙上强调,TileLang的目标是“桥接程序性与性能”。在实际应用中,这一目标已初见成效——据民生证券转述的测试数据,使用TileLang开发的部分算子在保持95%性能的同时,代码量减少至传统方法的十分之一。
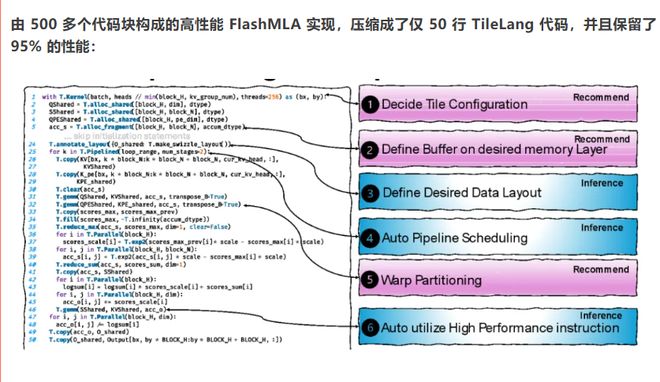
民生证券团队称,Tilelang的主要技术亮点包括:
1)简化NPU算子编程复杂度:Tilelang采用类Python语法,大大降低NPU算子开发门槛,封装调度空间为自定义原语,开发者更加关注数据流本身。2)支持灵活扩展:实现调度空间与数据流解耦,NPU算子优化由编译器自动完成,同时充分利用NPU底层硬件特性。
3)高性能:Tilelang可以实现高性能NPU算子,允许用户感知NPU硬件特性,相较Triton理论上可以获得更好的性能。