芯片公司Taalas将AI模型蚀刻到芯片电路中 性能达到惊人的每秒1.7万个Token
总部位于加拿大多伦多的芯片初创公司 Taalas 日前宣布完成 1.69 亿美元的新融资 (总融资超过 2.19 亿美元),同时该公司也正式宣布走出隐身模式开始对外展示其最新的核心技术。
Taalas 的核心技术是将大型语言模型 (LLM) 的部分结构 (特别是权重和计算逻辑) 直接硬编码 (蚀刻) 到硅芯片上,做成高度定制化的芯片,而不是像传统 GPU 那样将模型加载内存中运行。
这种硬件级固化的做法让大型语言模型变成“芯片本身就是模型”因此在进行模型计算时可以以极其夸张的速度吐出字符,例如 Taalas HC1 芯片单用户推理速度达到 17000+Tokens / 秒。

便于理解的比喻:
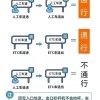
传统 GPU 将模型加载到内存中,运行时再读取和计算,这种情况下模型像是放在书架上的书籍,每次计算时芯片要反复将书籍从书架中拿出来、读取、计算、写回去,整个过程更加漫长并且功耗更高。
H1C 芯片则是将书籍中的内容直接刻到芯片的墙壁上 (通过晶体管和固定连线实现),芯片通电后,电路本身就长成模型的样子,数据流按照固定路径走而不需要反复读取内存,相当于芯片就是模型本身。
说起来这种技术其实和上时间 90 年代的门阵列非常相似,Taalas 的创新在于利用这种古老技术接近 LLM 参数稀疏性和量化带来的硬连线复杂性。

芯片即模型的技术原理:
这种硬件级固化的做法大部分是基于结构化 ASIC 和定制掩膜实现的,核心思路是将模型的权重和计算结构直接用晶体管和金属线蚀刻在硅芯片中。
Taalas 先做了个接近完成的芯片基础 (大约有 100 层金属 / 晶体管结构),大部分逻辑和存储已经做好,只保留最后两层金属 (掩膜) 用来做最终的定制。
而改变这两层金属就能把具体模型的权重和部分数据流路径写进去,这就像是印刷电路板时最后两层铜箔的图案决定具体功能,成本和时间都远远低于完全重新设计芯片。
该公司设计特殊的结构用很少的晶体管就能存储 4bit 权重 + 做乘法运算,权重不是写在可读写的内存中,而是像 ROM 只读存储器那样由掩膜决定晶体管导通或不导通的方式来硬编码数值。
在实际计算时不需要读取权重、乘法器、加法,而是电路本身就完成了乘法和加法运算,因为电路连线和晶体管已经按照权重配置好,剩余的小部分灵活性则依靠 SRAM (高速静态随机存储器),用来存储上下文缓存。
将模型蚀刻到芯片里的劣势:
计算机专业的小伙伴从上面的技术原理中应该已经知晓这种技术也存在根本性劣势,那就是模型蚀刻到芯片里就无法更改和升级,也就是这颗芯片只能使用这个模型。
首发芯片 HC1 蚀刻的是 Llama 3.1 8B 版,也就是这颗芯片从流片开始就只能使用这个模型,而目前 AI 行业发展速度极快,各种新模型层出不穷,这种不可更改和升级模型的做法就是最大的劣势。
不过 Taalas 称通过两层金属掩膜定制芯片全程只需要 2 个月左右,也就是至少从芯片角度来说设计新芯片运行新模型还是比较容易的,这应该有助于降低成本,而客户可能需要根据自己的需求不停地购买迭代后的芯片。