亚马逊“盲眼”机器人30秒跑酷首秀惊艳 华人学者领衔
你见过这样的“盲眼”机器人demo吗?它在完全看不见的情况下——没有摄像头、雷达或任何感知单元——主动搬起9斤重的椅子,爬上1米高的桌子,然后翻跟头跳下。

不光耍酷,干起活来,搬箱子也不在话下。

还能一个猛子跳上桌子。

手脚并用爬坡也照样OK。

这些丝滑小连招来自亚马逊机器人团队FAR(Frontier AI for Robotics)发布的首个人形机器人(足式)研究成果——OmniRetarget!
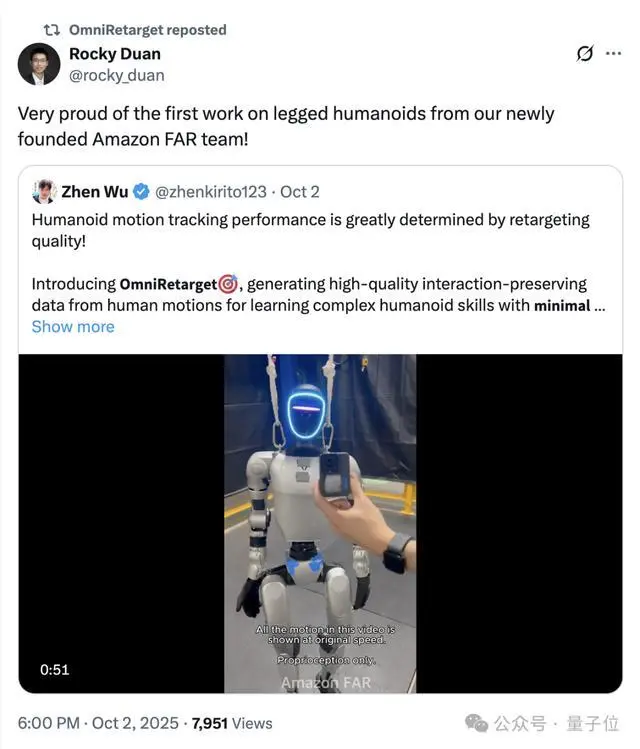
OmniRetarget使强化学习策略能够在复杂环境中学习长时程的“移-操一体”(loco-manipulation)技能,并实现从仿真到人形机器人的零样本迁移。

网友表示:又能跑酷、还能干活,这不比特斯拉的擎天柱强10倍?

接下来,让我们一起看看他们是怎么做到的吧!
基于交互网格的动作重定向方法
总的来说,OmniRetarget是一个开源的数据生成引擎,它将人类演示转化为多样化、高质量的运动学参考,用于人形机器人的全身控制。

与通常忽略人-物体/环境之间丰富的交互关系的动作重定向方法不同,OmniRetarget通过一个交互网格(interaction mesh)来建模机器人、物体和地形之间的空间和接触关系,从而保留了必要的交互并生成运动学可行的变体。
此外,保留任务相关的交互使得数据能够进行高效的数据增强,进而从单个演示推广到不同的机器人本体、地形和物体配置,以减少不同变体的数据收集成本。
在与其他动作重定向方法的对比中,OmniRetarget在所有关键方面:硬约束、物体交互、地形交互、数据增强表现出了全面的方法优势。

接下来就让我们具体来看。
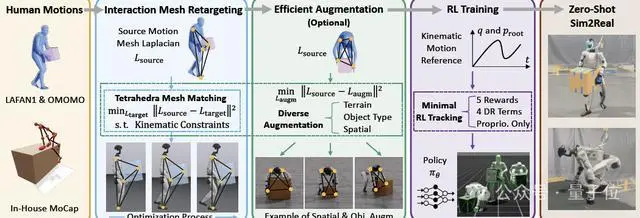
首先,OmniRetarget通过基于交互网格(interaction-mesh)的约束优化,将人类示范动作映射到机器人上。
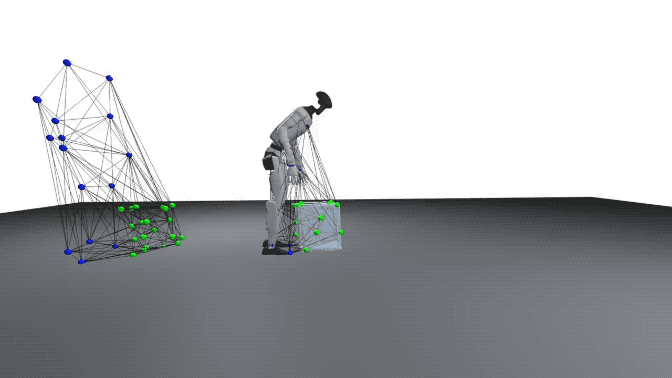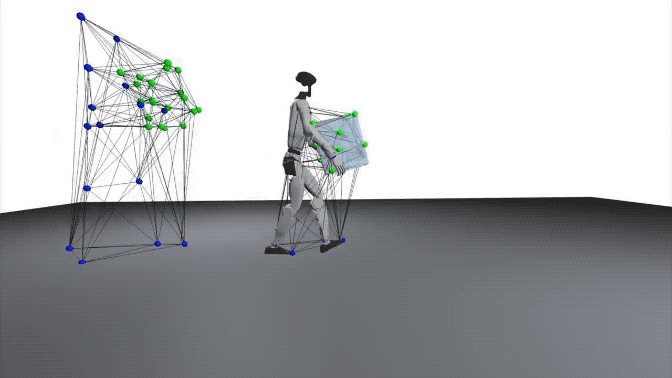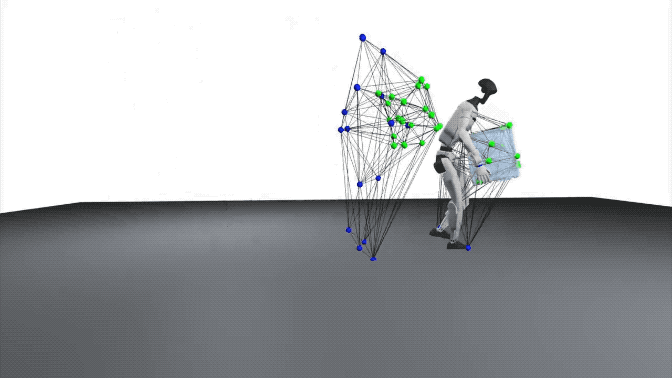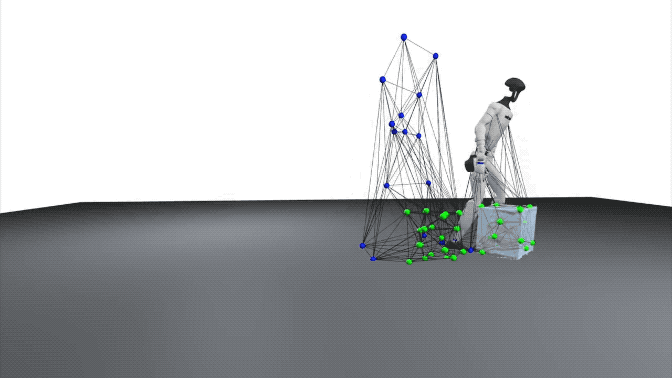
在研究中,交互网格被定义为一个体积结构,用于保持身体部位、物体与环境之间的空间关系。
交互网格的顶点由关键的机器人或人类关节以及从物体和环境中采样的点组成。
通过收缩或拉伸该网格,研究可以在保持相对空间结构和接触关系的前提下,将人类动作映射到机器人上。
在交互网格的构建过程中,研究人员对用户定义的关键关节位置以及随机采样的物体和环境点应用德劳内四面体化(Delaunay tetrahedralization)。
(注:为了更精确地保持接触关系,物体和环境表面的采样密度高于身体关节的采样密度。)
研究通过最小化源动作(人类示范关键点及对象/环境采样点)与目标动作(机器人对应关键点及相同对象/环境点)之间的拉普拉斯形变能(Laplacian deformation energy),让机器人动作尽量保持与人类示范一致的空间和接触关系。
拉普拉斯坐标衡量每个关键点与其邻居点之间的相对关系,从而在重定向动作时保留局部空间结构和接触关系。
在每个时间帧,算法通过求解约束非凸优化问题来获得机器人配置,包括浮动底座的姿态和平移以及所有关节角度,同时满足碰撞避免、关节和速度限制,以及防止支撑脚滑动等硬约束。
优化则使用顺序二次规划风格的迭代方法,每帧以上一帧的最优解作为初值,以保证时间上的连续性和平滑性。
由此,基于交互网格的方法可适配不同机器人形态和多种交互类型,只需调整交互网格中的关键点对应关系和碰撞模型。
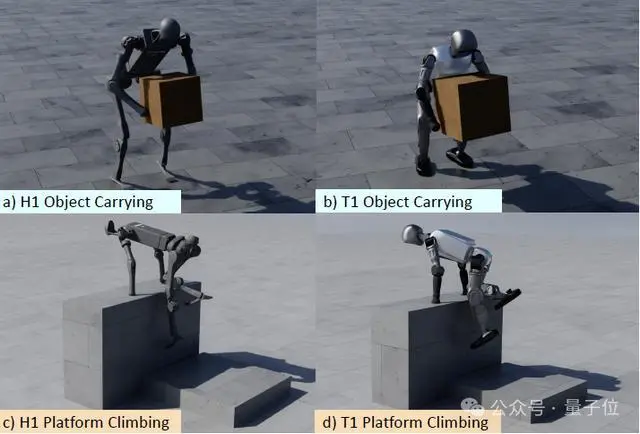
其次,每一次空间和形状的增强都被视为一个新的优化问题,从而生成多样化的轨迹。

具体来说,OmniRetarget通过参数化地改变物体配置、形状或地形特征,将单个人类演示转化为丰富多样的数据集。
对于每个新场景,研究都会使用固定的源动作集和增强后的目标动作集重新求解优化问题:通过最小化交互网格的形变,可以得到一组新的、运动学上有效的机器人动作,同时保留原始交互中的基本空间结构和接触关系。
在机器人-物体的交互中,研究通过增强物体的空间位置和形状来生成多样化的交互(位姿和平移进行增强,并在局部坐标系中构建交互网格)。
为避免整个机器人随物体发生简单刚体变换,研究还在优化中加入约束,将下半身固定到标称轨迹,同时允许上半身探索新的协调方式,从而生成真正多样化的交互动作。
在机器人-地形的交互中,研究通过改变平台的高度和深度,并引入额外约束来生成多样化的地形场景。
最后,在建立了高质量运动学参考的方法之后,研究使用强化学习来弥补动力学差异,即训练一个低层策略,将这些轨迹转化为物理可实现的动作,实现从仿真到硬件的零次迁移。
得益于干净且保留交互的参考数据,OmniRetarget仅需最小化奖励即可高保真跟踪,无需繁琐调参。
训练时,机器人无法直接感知明确的场景和物体信息,仅依赖本体感知和参考轨迹作为复杂任务的先验知识:
参考动作: 参考关节位置/速度,参考骨盆位置/方向误差
本体感受 : 骨盆线速度/角速度,关节位置/速度
先前动作: 上一时间步的策略动作
在奖励方面,研究使用五类奖励(身体跟踪、物体跟踪、动作速率、软关节限制、自碰撞)来保证动作质量,同时结合物体参数和机器人状态的领域随机化提升泛化能力。
此外,相似动作会分组训练以加快策略收敛,不同的任务(如搬箱和平台攀爬)则采用不同策略设置。

实验结论
在实验方面,研究团队首先展示了OmniRetarget能实现的复杂行为的广度,包括自然的物体操作和地形交互。
然后提供了针对最先进基线的定量基准测试,评估了在运动学质量指标和下游策略性能方面的表现。
正如我们开头所展示的,搭载OmniRetarget的宇树G1实现了一个类似波士顿动力的跑酷动作。
这个持续 30 秒、复杂的多阶段任务突显了OmniRetarget生成精确且通用参考动作的能力。
在可扩展性上,OmniRetarget在完整增强数据集上训练和评估成功率为79.1%,与仅使用标称动作的82.2%相近,说明运动学增强在不显著降低性能的情况下实质性扩大了动作覆盖范围。
最后,研究团队将OmniRetarget与PHC、GMR和VideoMimic等开源重定向基线进行了比较。
(注:实验使用OMOMO、内部MoCap和LAFAN1数据集进行评估)
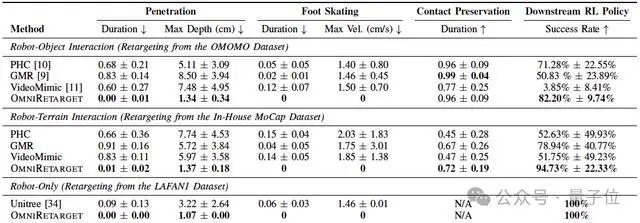
实验结果显示,在运动学质量上,OmniRetarget在穿透、脚部打滑和接触保留指标上整体优于所有基线,即使偶尔轻微穿透也能被 RL 修复。
下游强化学习策略评估表明,高质量重定向动作直接提升策略成功率,OmniRetarget在所有任务中均领先基线 10% 以上,且表现更稳定。
One more thing
值得一提的是,OmniRetarget背后的Amazon FAR (Frontier AI & Robotics)成立仅七个多月,由华人学者领衔。
FAR的前身是著名机器人技术公司Covariant,创始人均为出自UCBerkeley的Pieter Abbeel、Peter Chen、Rocky Duan 和Tianhao Zhang。
(注:Pieter Abbeel是Rocky Duan和Tianhao Zhang的导师)
其中,Pieter Abbeel可谓是机器人领域的大佬,他是伯克利机器人学习实验室(Berkeley Robot Learning Lab)主任以及伯克利人工智能研究实验室(Berkeley AI Research, BAIR)的联合主任。

早在去年8月,亚马逊就与Covariant达成协议,获得该公司技术的“非排他性”许可,聘用Covariant四分之一的员工,同时Covariant的创始人Pieter Abbeel、Peter Chen、和Rocky Duan也将加入亚马逊。
目前,由Rocky Duan担任Amazon FAR研究负责人。
而OmniRetarget这次令人惊艳的亮相,正是Amazon FAR 在人形机器人(足式)领域的首次尝试。
不得不说,亚马逊(Amazon)的机器人,真的有点惊艳(Amazing)。
已经开始期待他们之后的工作了!
参考链接:
[1]https://x.com/Thom_Wolf/status/1974774416815857779
[2]https://www.aboutamazon.com/news/company-news/amazon-covariant-ai-robots
[3]https://analyticsindiamag.com/ai-news-updates/amazon-forms-frontier-ai-robotics-team-to-revolutionise-automation/
[4]https://OmniRetarget.github.io/